爬虫中网页数据获取后的三种处理方法

爬虫如风,常伴吾身……
在日常的折腾中,无论是我的网站被人爬,还是别人的网站被我爬,这像是一个博弈的过程。双方在“隐形条约”下完成自己的任务,正所谓君子之交淡如水,我不知道他是谁,他也不知道我是谁,我们互相为对方提供所需要的信息。或许这种关系更像是江湖,纯粹的江湖,不讲莺莺燕燕和人情世故。只讲轻舟江上对饮,竹林剑鸣,点到为止。而后双方收剑而去,更不会有人啰嗦着问一句:“来将何人?报上名来。” 爬虫中重要的一环就是数据处理。虽然静态加载的网页结构千差万别,界面看起来也各有特色,但爬取到的数据是单一的,都是DOM结构“子孙”。即使明白筛选数据的本质就是处理字符串,但其中的处理办法也层出不穷。以下根据不同的网页风格,对症下药。 一:“好孩子”式网页 特点:有完整的DOM结构,虽然有的时候采用“乱七八糟”的编码,如:gb2312等,但它的本质还是个“好孩子”。 示例网址:百度搜索风云榜 http://top.baidu.com/buzz?b=1  分析:查看源码可以简单的看出风云榜的新闻格式均为
分析:查看源码可以简单的看出风云榜的新闻格式均为
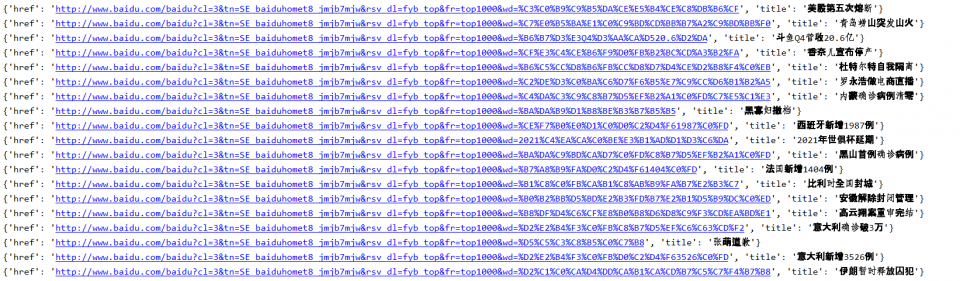
解析办法: 1,使用BeautifulSoup 部分代码如下: from bs4 import BeautifulSoup as soup source_code = “……” #你获取到的网页源代码 soup_dom = soup(source_code,’lxml’) all_a = soup_dom.find_all(‘a’,attrs={‘class’:’list-title’}) for a in all_a: href_title = {‘href’:a.get(‘href’),’title’:a.text} 结果如下:
2,使用xpath方法解析 部分代码如下: from lxml import etree source_code = “……” #你获取到的网页源代码 all_a = etree.Html(source_code).xpath(“//a[@class=’list-title’]“) for a in all_a: href_title = {‘href’:a.attrib[‘href’],’title’:a.text} print(href_title) 结果如下:
从以上两种方法可以看出,获取“好孩子”式网页的数据可以使用bs4或者Xpath。毕竟管教“好孩子”的成本要远远低于管教“坏孩子”的成本,这也就是为什么大家都喜欢好孩子。 二:“坏孩子”式网页 特点:多为远古时期的网页(2010年以前),DOM乱七八糟。(有的网页甚至只有一个封闭标签,剩下的竟然都是由
标签进行分割,更有甚者使用假的API网页来“冒充”真正的API。) 但是:此类网址多为大牛博客,他们不拘一格,当你发现的时候就像在断崖下发现秘籍一样! 示例网址:清华大学Penny Hot 在2003年写的linuxc的教程 http://net.pku.edu.cn/~yhf/linux\_c/ 分析:能用简单办法就用简单办法,实在不行就用正则  在此再次郑重感谢PennyHot,在2003年将自己得到的一份Linux C 文档整理出来方便大家!
在此再次郑重感谢PennyHot,在2003年将自己得到的一份Linux C 文档整理出来方便大家!
解决办法:使用正则 示例代码: import re source_code = “……” #你获取到的网页源代码 compile = re.compile(“[\u4e00-\u9fa5]*“) #尽可能多的匹配中文 find_all = compile.findall(source_code) for i in find_all: if i !=””: print(i) 结果如下:

总结:万法归宗,没有好的方法,只要是能获取到自己需要的数据,就是好方法。 最后再再次感谢那些为互联网后来者做出贡献的先辈们,即使很多人都做着普通的工作,但是他们留下的东西像宝藏一样,藏宝图隐藏在互联网的各个角落。吾辈当自强! 2020.3.19 Wicos